

JDK 9 reached General Availability on 21 September 2017, and it comes with a list of new and revised features, methods, and other elements.
In the following post we take a deeper look into JEP 266, go over the improvements it has to offer. So let's start ;)
Reactive Streams
When Reactive Streams started their work, following the path established by the Reactive Manifesto, they indicated that their aim was to provide "a standard for asynchronous stream processing with non-blocking back pressure". The main challenge, however, wasn't to find a solution, in particular since there were already a number of them out there. The challenge was to coalesce the different existing patterns into a common one to maximise interoperability. More precisely, the objective of Reactive Streams was “to find a minimal set of interfaces, methods and protocols that will describe the necessary operations and entities to achieve the goal—asynchronous streams of data with non-blocking back pressure”.
The concept of "back pressure" is key. When an asynchronous consumer subscribes to receive messages from a producer, it will typically provide some form of callback method to be invoked whenever a new message becomes available. If the producer emits messages at a higher rate than the consumer can handle, the consumer could be forced to seize an increasing amount of resources and potentially crash. In order to prevent this, a mechanism is needed by which consumers can notify producers that the message rate needs to be reduced. Producers can then adopt one of multiple strategies to achieve this. This mechanism is called back pressure.
Blocking back pressure is easy to achieve. If, for instance, producer and consumer are running under the same thread, the execution of one will block the execution of the other. This means that, while the consumer is being executed, the producer cannot emit any new messages, and therefore a natural way to balance input and output occurs. However, there are scenarios where blocking back pressure is undesirable (for instance when a producer has multiple consumers, not all of them consuming messages at the same rate) or simply unattainable (for instance when consumer and producer run in different environments). In these cases it is necessary that the back pressure mechanism works in a non-blocking way.
The way to achieve non-blocking back pressure is to move from a push strategy, where the producer sends messages to the consumer as soon as these are available, to a pull strategy, where the consumer requests a number of messages to the producer and this sends only up to this amount, waiting for further requests before sending any more.
JEP 266: More Concurrency Updates
The Flow APIs in JDK 9 correspond to the Reactive Streams Specification, which is a defacto standard. JEP 266 contains a minimal set of interfaces that capture the heart of asynchronous publication and subscription. The hope is that in the future 3rd parties will implement them and thus convene on a shared set of types.
And here they are:
Publisher
Produces items for subscribers to consume. The only method is subscribe(Subscriber), whose purpose should be obvious.
Subscriber
Subscribes to publishers (usually only one) to receive items (via method onNext(T)), error messages (onError(Throwable)), or a signal that no more items are to be expected (onComplete()). Before any of those things happen, though, the publisher calls onSubscription(Subscription).
Subscription
The connection between a single publisher and a single subscriber. The subscriber will use it to request more items (request(long)) or to sever the connection (cancel()).
The flow is as follows:
- Create a
Publisherand aSubscriber. - Subscribe the subscriber with
Publisher::subscribe. - The publisher creates a Subscription and calls
Subscriber::onSubscriptionwith it so the subscriber can store the subscription. - At some point the subscriber calls
Subscription::requestto request a number of items. - The publisher starts handing items to the subscriber by calling
Subscriber::onNext. It will never publish more than the requested number of items. - The publisher might at some point be depleted or run into trouble and call
Subscriber::onCompleteorSubscriber::onError, respectively. - The subscriber might either continue to request more items every now and then or cut the connection by calling
Subscription::cancel.
All of this is pretty straight forward, maybe with the exception of Subscription::request. Why would the subscriber need to do that? This is the implementation of back pressure explained above ;)
Time for action
The basic idea is to make use of Reactive Streams to stream tweets from a Twitter search. For that will use the well known Twitter4J library.
First off, we need to implement a Publisher and a Subscriber.
TweetSubscriber.java
The Subscriber should implement the Flow.Subscriber interface and override three main methods:
onComplete()which gets called when there is no more items are to be expectedonError(Throwable)which is a separate channel for errors that you should listen on for errors.onNext(T)which is used to retrieve the next item(s).- Before any of those things happen, though, the publisher calls
onSubscription(Subscription).
public class TweetSubscriber implements Flow.Subscriber<Status> {
private final String id = UUID.randomUUID().toString();
private Flow.Subscription subscription;
private static final int SUB_REQ=1;
private static final int SLEEP=1000;
@Inject
private Logger logger ;
@Override
public void onSubscribe(Flow.Subscription subscription) {
logger.info( "subscriber: "+ id +" ==> Subscribed");
this.subscription = subscription;
subscription.request(SUB_REQ);
}
@Override
public void onNext(Status status) {
try {
Thread.sleep(SLEEP);
} catch (InterruptedException e) {
logger.log(Level.SEVERE,"An error has occured: {}", e);
}
Tweet t = new Tweet(status.getUser().getScreenName(), status.getText(), status.getCreatedAt());
logger.info("New Tweet: --->");
System.out.println(t.toString());
subscription.request(SUB_REQ);
}
@Override
public void onError(Throwable throwable) {
logger.log(Level.SEVERE, "An error occured: {}", throwable);
}
@Override
public void onComplete() {
logger.info("Done!");
}
}
This is pretty much self-explanatory. The interesting part is the onNext method, where I instantiate a tweet object and print it. The 1s sleep is to simulate some very expensive computing (and for readability purposes).
TweetPublisher
Let's take a look at our publisher before exploring it piece by piece:
public class TweetPublisher implements Flow.Publisher {
private static final int CORE_POOL_SIZE = 1;
private static final int NB_THREADS = 1;
private static final int INITIAL_DELAY = 1;
private static final int DELAY = 5;
@Inject
@Property("consumerKey")
private String _consumerKey;
@Inject
@Property("consumerSecret")
private String _consumerSecret;
@Inject
@Property("accessToken")
private String _accessToken;
@Inject
@Property("accessTokenSecret")
private String _accesessTokenSecret;
@Inject
@Property("query")
private String query;
@Inject
private Logger logger;
private Query twitterQuery;
private final ExecutorService EXECUTOR = Executors.newFixedThreadPool(NB_THREADS);
private Twitter twitter;
private SubmissionPublisher<Status> sb = new SubmissionPublisher<Status>(EXECUTOR, Flow.defaultBufferSize());
private Map<Long, Object> tweetCache = new HashMap<>();
@PostConstruct
public void setup() {
twitterQuery = new Query(query);
twitterQuery.setResultType(Query.ResultType.mixed);
ConfigurationBuilder cb = new ConfigurationBuilder();
cb.setDebugEnabled(true).setOAuthConsumerKey(_consumerKey)
.setOAuthConsumerSecret(_consumerSecret)
.setOAuthAccessToken(_accessToken)
.setOAuthAccessTokenSecret(_accesessTokenSecret);
TwitterFactory tf = new TwitterFactory(cb.build());
twitter = tf.getInstance();
}
public void getTweets(){
ScheduledExecutorService executor = Executors.newScheduledThreadPool(CORE_POOL_SIZE);
Runnable tweets = () -> {
try {
twitter.search(twitterQuery).getTweets()
.stream()
.filter(status -> !tweetCache.containsKey(status.getId()))
.forEach(status -> {
tweetCache.put(status.getId(), null);
sb.submit(status);
});
} catch (TwitterException e) {
logger.log(Level.SEVERE, "AN error occured while fetching tweets: {}", e);
}
};
executor.scheduleWithFixedDelay(tweets, INITIAL_DELAY, DELAY, TimeUnit.SECONDS);
}
@Override
public void subscribe(Flow.Subscriber subscriber) {
sb.subscribe(subscriber);
}
}
Our publisher make use of SubmissionPublisher. The SubmissionPublisher class uses the supplied Executor, which delivers to the Subscriber. We are free to use any Executor depending upon the scenario in which we are working on. In our case we've created SubmissionPublisher with a fixed thread pool of 1.
The setup method configure and instantiate out Twitter and Query instance.
Next, I define a Scheduler to run every 5 seconds a search on Twitter for the query. tweetCache Map plays the role of a cache to prevent from printing same tweet twice.
The subscribe method takes a Flow.Subscriber and subscribes it to the SubmissionPublisher.
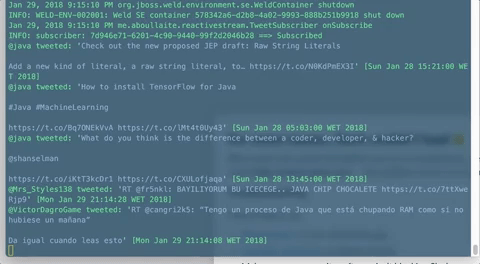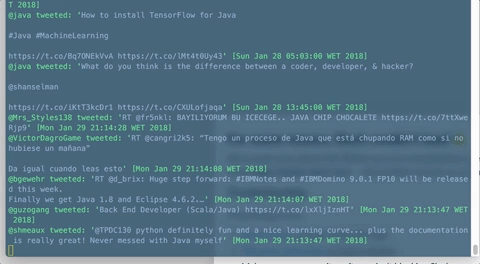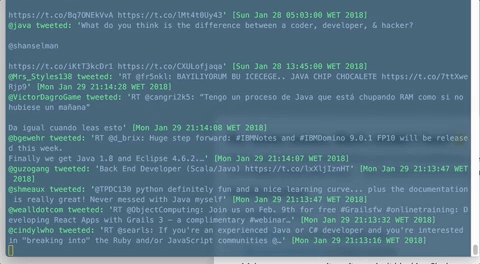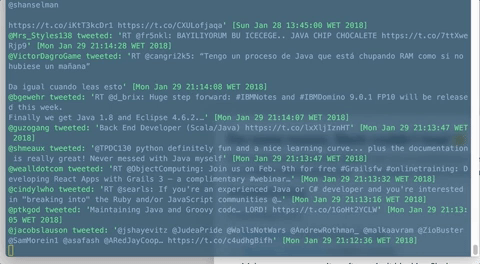
Final result
Here's our very basic reactive stream example in action
Ton run it locally, you need to create a twitter app and add the secrets in application.properties file.
